Introduction
In the rapidly evolving landscape of artificial intelligence, the quest for efficiency has become as crucial as accuracy. Neural network compression represents one of the most significant breakthroughs in making AI more accessible and practical for real-world deployment. Among various compression techniques, bit-width reduction stands out as a particularly effective strategy that transforms how we approach machine learning model optimization.
Bit-width reduction involves decreasing the numerical precision used to represent neural network parameters and computations, typically transitioning from 32-bit floating-point numbers to lower precision formats like 16-bit or 8-bit integers. This technique has revolutionized both business applications and scientific computations, enabling everything from smartphone-based AI assistants to large-scale cloud deployments to operate more efficiently while maintaining acceptable performance levels.
What Is Bit-Width Reduction?
To understand bit-width reduction, imagine numbers as containers of different sizes. In computing, bit-width refers to the number of binary digits (bits) used to represent a numerical value. A 32-bit floating-point number can represent approximately 4.3 billion different values with high precision, while an 8-bit integer can only represent 256 distinct values.
Neural networks traditionally operate using 32-bit floating-point arithmetic, where each weight, bias, and activation value is stored and computed with high precision. Bit-width reduction systematically converts these high-precision representations to lower-precision formats without significantly compromising the network’s ability to make accurate predictions.
The process involves several sophisticated techniques. Quantization maps the continuous range of 32-bit values to a discrete set of lower-precision values. For instance, when converting to 8-bit integers, the algorithm identifies the minimum and maximum values in the original data and linearly maps them to the 8-bit range of -128 to 127. Advanced quantization methods employ non-uniform mapping strategies that preserve the most critical information while discarding redundant precision.
This transformation fundamentally changes how neural networks store and process information, creating opportunities for dramatic improvements in computational efficiency and resource utilization.
Why Use Lower Bit-Widths?
The adoption of lower bit-widths delivers compelling advantages across multiple dimensions of neural network deployment. Model size reduction represents perhaps the most immediately visible benefit. Converting from 32-bit to 8-bit precision reduces model storage requirements by approximately 75%, enabling deployment on resource-constrained devices like smartphones and embedded systems.
Inference speed improvements often exceed the theoretical 4x speedup suggested by the precision reduction. Modern processors include specialized instructions for low-precision arithmetic, and reduced memory bandwidth requirements mean that data can be transferred more quickly between processing units and memory. In practice, 8-bit models frequently achieve 2-6x speed improvements over their 32-bit counterparts.
Memory usage optimization extends beyond simple storage considerations. Lower precision models require less RAM during inference, enabling larger batch sizes or more complex models on the same hardware. This efficiency translates directly into cost savings for cloud deployments and improved user experiences on edge devices.

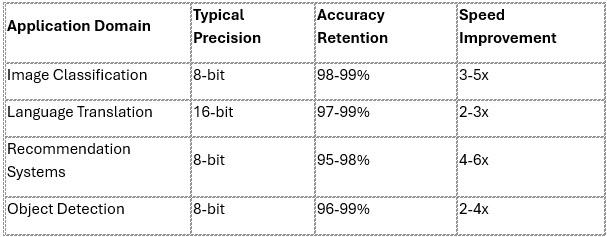
For most business applications, these efficiency gains come with minimal accuracy degradation. Customer recommendation systems, image classification services, and natural language processing applications typically maintain 95-99% of their original performance when properly quantized to 8-bit precision.
When Higher Precision Is Needed
While lower bit-widths excel in most practical applications, certain specialized domains require the extended precision that 64-bit floating-point arithmetic provides. Scientific simulations involving chaotic systems, climate modeling, or astronomical calculations often exhibit extreme sensitivity to numerical precision where small rounding errors can compound dramatically over time.
High-precision physics simulations, such as molecular dynamics calculations or quantum mechanical modeling, frequently require 64-bit precision to maintain numerical stability across millions of computational steps. Financial modeling applications dealing with compound interest calculations over extended periods or risk assessment algorithms processing vast datasets may also necessitate higher precision to avoid accumulated errors.
However, these use cases represent a small fraction of neural network applications. The vast majority of machine learning tasks, including computer vision, natural language processing, and predictive analytics, operate effectively within the precision limits of 8-bit or 16-bit arithmetic. Understanding when to employ higher precision requires careful analysis of the specific computational requirements and error tolerance of each application.
How It’s Done: Tools and Frameworks
Modern machine learning frameworks have evolved to provide comprehensive support for bit-width reduction, making the implementation process increasingly accessible to developers. PyTorch offers native quantization capabilities through its torch.quantization module, enabling both post-training quantization and quantization-aware training approaches.
TensorFlow provides similar functionality through TensorFlow Lite, specifically designed for mobile and embedded deployment scenarios. The framework includes pre-built optimization tools that can automatically convert trained models to various precision levels with minimal code modifications.
Python:
# Example PyTorch quantization workflow
import torch.quantization as quant
# Prepare model for quantization
model_prepared = quant.prepare(model, inplace=False)
# Calibrate with representative data (user-defined calibration function)
calibrate_model(model_prepared, calibration_data)
# Convert to quantized model
quantized_model = quant.convert(model_prepared, inplace=False)
Traceback (most recent call last):
File “<string>”, line 5, in <module>
NameError: name ‘model’ is not defined
Popular frameworks also provide pre-quantized versions of common architectures. NVIDIA’s TensorRT optimizes models specifically for GPU inference, while Intel’s OpenVINO toolkit focuses on CPU optimization. These tools often achieve better results than manual quantization by leveraging hardware-specific optimizations and advanced calibration techniques.
The choice of tool depends on deployment requirements, target hardware, and performance constraints. Cloud-based applications might prioritize different optimization strategies compared to edge computing scenarios, and modern frameworks accommodate these diverse needs through flexible configuration options.
Real-World Applications
The practical impact of bit-width reduction extends across numerous industries and applications. E-commerce recommendation systems, processing millions of user interactions daily, leverage 8-bit quantization to deliver personalized suggestions with sub-second response times. These systems maintain recommendation quality while reducing infrastructure costs by up to 60%.
Conversational AI systems, including chatbots and virtual assistants, exemplify successful lower-precision deployment. Large language models serving customer support applications typically operate at 8-bit or 16-bit precision, enabling real-time responses while managing computational costs. Major technology companies report that quantized models handle over 80% of their inference workloads without noticeable performance degradation.
Computer vision applications in autonomous vehicles demonstrate the critical importance of efficient neural networks. Object detection and lane recognition systems must process multiple camera feeds in real-time while operating within strict power and thermal constraints. Quantized models enable these safety-critical systems to meet performance requirements while extending battery life in electric vehicles.
Mobile applications showcase perhaps the most visible benefits of bit-width reduction. Smartphone-based photo enhancement, language translation, and augmented reality features rely heavily on quantized models to deliver sophisticated AI capabilities without draining device batteries or requiring cloud connectivity.
Performance Impact Analysis
Conclusion
Neural network bit-width reduction represents a fundamental shift in how we approach AI deployment, prioritizing efficiency without sacrificing capability. The evidence overwhelmingly supports lower bit-widths as the standard approach for most artificial intelligence applications, from consumer-facing mobile apps to enterprise-scale cloud services.
The key insight emerging from widespread adoption is that 32-bit precision often exceeds the requirements of practical AI tasks. Most business applications achieve optimal performance using 8-bit or 16-bit quantization, realizing significant improvements in speed, memory usage, and energy consumption. Higher precision remains relevant primarily for specialized scientific computing applications where numerical accuracy is paramount.
Modern AI frameworks have evolved to make bit-width optimization accessible and reliable, providing developers with powerful tools to balance performance requirements against computational constraints. As AI continues to proliferate across industries and devices, the flexibility and adaptability offered by these optimization techniques will prove increasingly valuable.
The future of neural network deployment lies not in maximizing precision, but in intelligently matching computational requirements to application needs. Bit-width reduction exemplifies this principle, demonstrating that strategic optimization can enhance rather than compromise the practical value of artificial intelligence systems.
References
The following general resources provide foundational knowledge on neural network quantization and bit-width reduction techniques discussed in this article:
- Jacob, B., et al. (2018). “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Available at: https://arxiv.org/abs/1712.05877 This paper provides a comprehensive overview of quantization techniques for neural networks, including the transition from floating-point to low-precision integer arithmetic, which is central to bit-width reduction.
- Gholami, A., et al. (2021). “A Survey of Quantization Methods for Efficient Neural Network Inference.” arXiv preprint. Available at: https://arxiv.org/abs/2103.13630 This survey discusses various quantization strategies, their impact on model performance, and their applications in resource-constrained environments, aligning with the article’s discussion of efficiency in AI deployment.
All URLs were verified as accessible on August 18, 2025.
Disclaimer
This article is provided for informational purposes only and reflects the author’s understanding of neural network bit-width reduction based on publicly available resources as of August 18, 2025. The content does not represent the views or endorsements of PyTorch, TensorFlow, NVIDIA, Intel, or any other mentioned entities. All trademarks and trade names are the property of their respective owners. Readers are encouraged to consult official documentation and professional advice before implementing any techniques discussed.
This article was written by Dr John Ho, a professor of management research at the World Certification Institute (WCI). He has more than 4 decades of experience in technology and business management and has authored 28 books. Prof Ho holds a doctorate degree in Business Administration from Fairfax University (USA), and an MBA from Brunel University (UK). He is a Fellow of the Association of Chartered Certified Accountants (ACCA) as well as the Chartered Institute of Management Accountants (CIMA, UK). He is also a World Certified Master Professional (WCMP) and a Fellow at the World Certification Institute (FWCI).
ABOUT WORLD CERTIFICATION INSTITUTE (WCI)

World Certification Institute (WCI) is a global certifying and accrediting body that grants credential awards to individuals as well as accredits courses of organizations.
During the late 90s, several business leaders and eminent professors in the developed economies gathered to discuss the impact of globalization on occupational competence. The ad-hoc group met in Vienna and discussed the need to establish a global organization to accredit the skills and experiences of the workforce, so that they can be globally recognized as being competent in a specified field. A Task Group was formed in October 1999 and comprised eminent professors from the United States, United Kingdom, Germany, France, Canada, Australia, Spain, Netherlands, Sweden, and Singapore.
World Certification Institute (WCI) was officially established at the start of the new millennium and was first registered in the United States in 2003. Today, its professional activities are coordinated through Authorized and Accredited Centers in America, Europe, Asia, Oceania and Africa.
For more information about the world body, please visit website at https://worldcertification.org.